Problem Description¶
The Williams-Otto CSTR is a benchmark process for real-time optimization (RTO) systems. It consists in the following reactions:
$ A + B \rightarrow C $ (1)
$ B + C \rightarrow P + E $ (2)
$ C + P \rightarrow G $ (3)
where A and B are raw materials, P is the desired product, E is the byproduct with added sales value, C is the complex intermediate without sale value, and G is the residual material. The reactor is fed by two reactant flow rates (Fa and Fb). The full set of mass balance equations can be found in [1], for example.
Each reaction has its rate $k$ defined as a function of the reactor temperature Tr:
$ k_1 = 1.6599\times10^6\exp(-6666.7/Tr) $
$ k_2 = 7.2177\times10^8\exp(-8333.3/Tr) $
$ k_3 = 2.6745\times10^{12}\exp(-11111/Tr) $
Fa assumes a fixed, therefore Fb and Tr are our manipulated (decision) variables, $u=[Fb, Tr]$. The optimization objective is finding a combination of these variables in order to maximize the profit when the system reaches steady-state operation:
$ \Phi(u) = 1043.38*Xp*(Fa+Fb)+20.92*Xe*(Fa+Fb) - 79.23*Fa - 118.34*Fb$
where $Xp$ and $Xe$ are the amount of P and E in steady-state operation, respectively. Besides steady-state operation, the following operational constraints are enforced:
$Fb \in [3,6]$
$Tr \in [70, 100]$
$Xa < 0.12$
$Xg < 0.08$
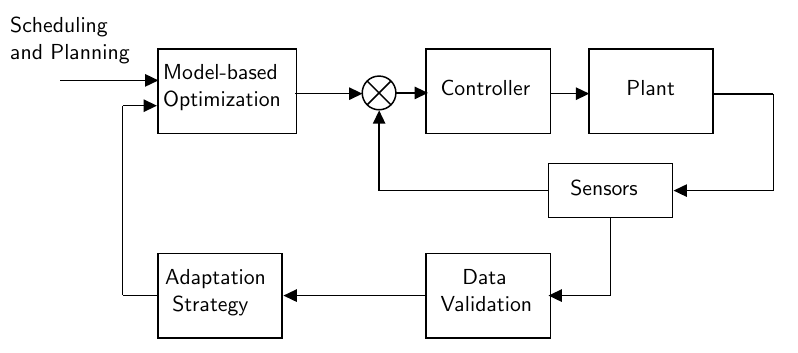
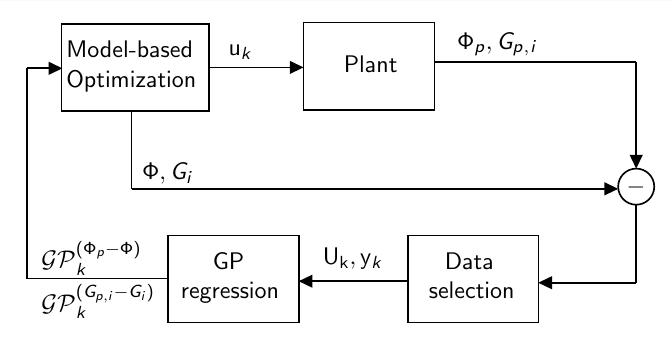
In practice, however, it is very unlikely to know the complete model of a given process. It can be in the form of parametrical and/or structural mismatch. Parametrical mismatch means we know the model structure, but its parameters are uncertain. Structural mismatch is the case where we the complete model equations are unknown, which usually happens when trying to model complex processes and have to apply simplifications to some of its behaviors. It is easy to see that if we try to optimize a process based on a uncertain model, we can produce sub-optimal or even unfeasible operating points. This is where RTO systems come to the rescue: they are specifically designed to handle model uncertainty and lead to process optimality under convergence.
For the Williams-Otto CSTR we know all the process equations and parameters. Therefore, to study the real-time optimization capabilities, we will use a simplified version of this model in order to simulate what would happen in real applications. For that, we consider the following model structure:
$ A + 2B \rightarrow P + E $ (1)
$ A + B + P \rightarrow G $ (2)
And the reaction rates are given by:
$ k_1 = 1.655\times10^8\exp(-8077.6/Tr) $
$ k_2 = 2.611\times10^{13}\exp(-12438.5/Tr) $